Python-Challenge(上)
在家无事,翻阅有道云笔记中前几年的资料发现了完成了一半的Python-Challenge游戏,本文是几年前写的内容。

今天来玩一款小游戏,python解谜闯关网站,链接是www.pythonchallenge.com
本文含有大量剧透,攻略向,看到感兴趣想动手试试的时候请紧急刹车。
自己动手,乐趣无穷。
0
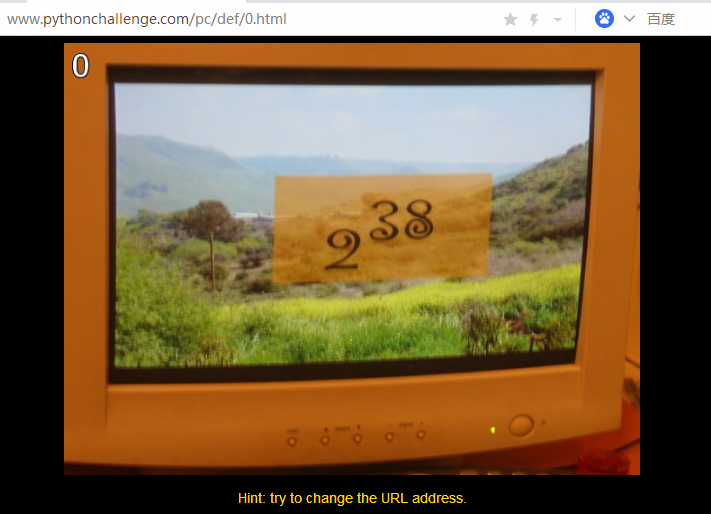
根据提示要改变url,也就是url http://www.pythonchallenge.com/pc/def/0.html 的0,根据图片中的2^38,在python交互模式中输入2**38,得到274877906944L,其中L表示长整型。
在浏览器输入 http://www.pythonchallenge.com/pc/def/274877906944.html 让我们进入下一关。
1
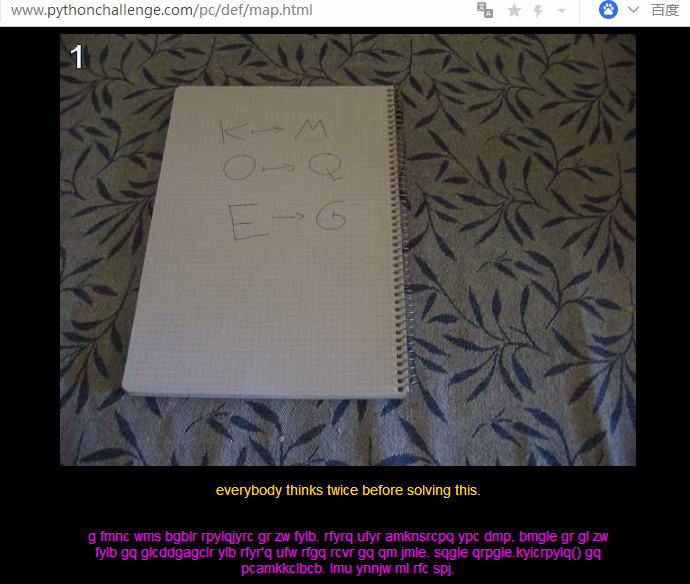
给了这样一串英文:
g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr’q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj.
提示是:K -> M ; O -> Q ; E -> G
这一关应该是把那一串字符按照规则解谜,首先发现只做上面三条替换还是得不到通顺的句子,而上面三条规则都是替换了ASCII + 2的字母,所以每个字母都应该这样处理(y z要额外减去26)。
一开始用了很笨的方法,用ord() 方法将字母转化为ASCII码做+2(或-24)处理,然后再用chr()把ASCII码转化为字母。
解密之后得到这样一句话:
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that’s why this text is so long. using string.maketrans() is recommended. now apply on the url.
按照提示和现有url:http://www.pythonchallenge.com/pc/def/map.html ,改进了代码,试了一下
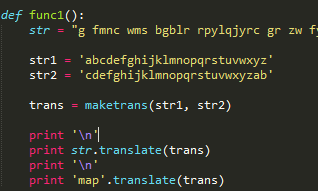
map –> ocr,新的url是:http://www.pythonchallenge.com/pc/def/ocr.html
2
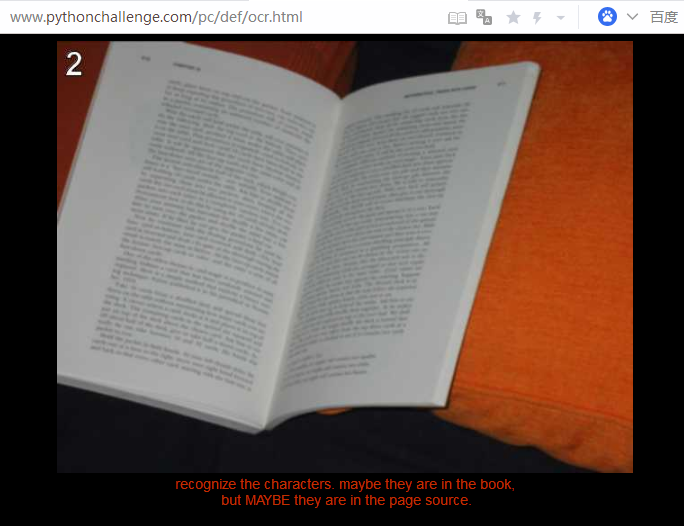
打开html,在一个隐蔽的角落里藏了一大坨乱码字符,大概是下面这样

眼尖的室友发现其中夹杂着一些小写字母,不管,先保存到html1.txt,再筛选出来。
筛选a~z之间的字母,最后连成一个单词 equality
得到下一关的url :http://www.pythonchallenge.com/pc/def/equality.html
3
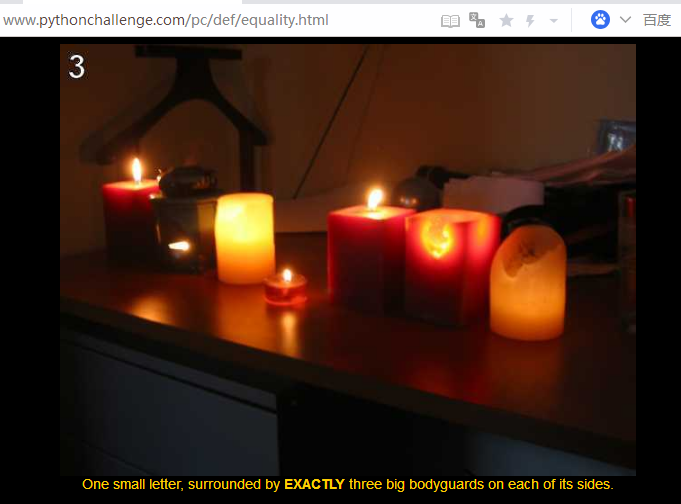
题目意思是,找出前后分别只有三个大写字母的小写字母。
这里可以看到网页的标签是re,提示我们使用re

按照上一题的尿性,也是在html里发现一大堆乱码,也是先存在html2.txt下。
在程序前面import re,下面是源代码

运行结果是 linkedlist
所以新的url是:http://www.pythonchallenge.com/pc/def/linkedlist.html
跳转的时候发现网页提示linkedlist.php,所以把html改成php跳转第四关
4

没有任何提示
好吧,研究了半分钟,决定乱点。
发现点了上面那张图的下半张,会跳转一个网页,上有一句话
and the next nothing is 44827
我们发现这时的url已经变成:
http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345
所以改一下nothing=44827:
http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=44827
继续修改:
http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=45439
Your hands are getting tired and the next nothing is 94485
…….
在手动输入了很多次之后,我觉得还是应该写一个程序(md,浪费了好久)
返回头来看网站源码里有一句不超过四百次,我才知道我完全走入了误区。
在这里应该还是用正则匹配和爬虫抓取,(我去恶补完又回来了)学会了简单的使用,解决这一关应该是没问题了。
在import urllib2之后,代码如下,在nothing = ‘12345’, n = 400的时候运行。
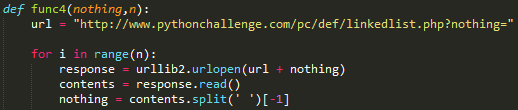
这里没有使用正则匹配,怕他又玩什么幺蛾子,就这样,我运行了一会觉得不对劲,于是加了输出。
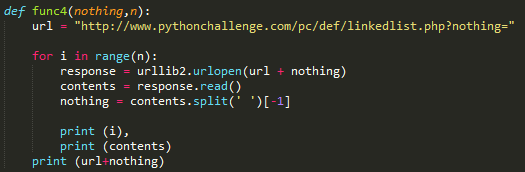
在nothing=16044的时候,网页的输出是Divide by two and keep going
于是ctrl + c 手动停止程序,把参数调整为nothing = ‘8022’ , n = 315 运行
这里太多懒得写了。。。
5
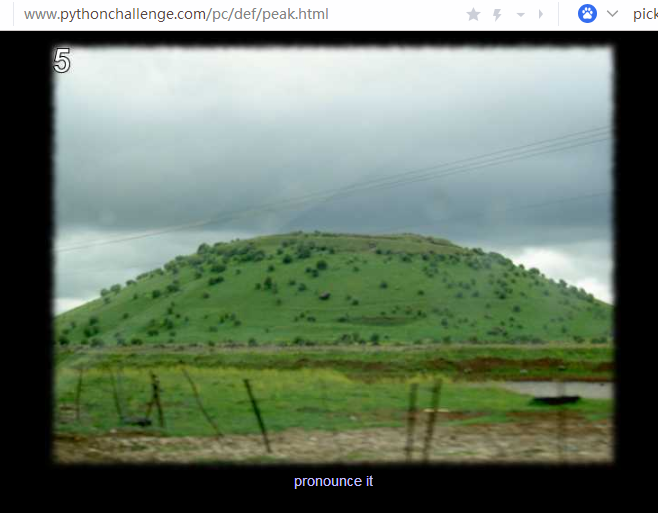
让我们读出图片中的山(应该是英文吧)查了一下源代码后发现
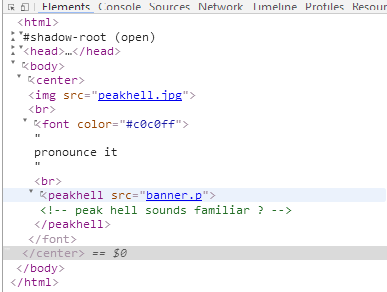
应该是读 peak hell sounds familiar what?
这里要考谐音,同时这个谐音应该还和python当中的某个包或者函数有关。
(我就是在这里看了攻略,初学python,不识pickle)
Google之后才知道有一个叫pickle的包,感兴趣的可以百度一下pickle是啥。
用迅雷贴上链接下载了 banner.p ,其实也可以url抓取。
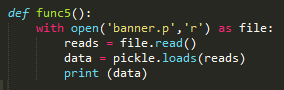
Print 之后发现返回的是一个列表
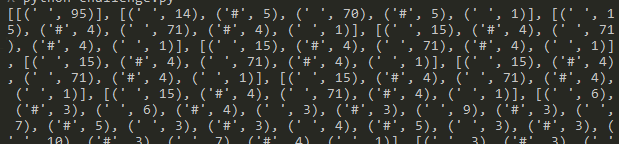
列表里的每个元组由一个字符,一个数字组成。
这里猜一下,是不是一个由字符组成的画,上面有去往下一关的线索。
[[(‘ ‘, 95)], [(‘ ‘, 14), (‘#’, 5), (‘ ‘, 70), (‘#’, 5), (‘ ‘, 1)],
猜一下这个意思是指:
第一行有95个空格;
第二行14个空格 + 5个’#’ + 70个空格 + 5个’#’ + 1个空格
······
添加如下代码
结果如下,哈哈哈,下一关走起!
当时好像不止打到第五关,但是因为懒得记录就停了。
在这里偷偷记录下大学的时候吧,头一年有点迷茫,以前只要考高分,现在却没有了明确的目标,天天在图书馆泡着看了好多闲杂书,大二的时候呢终于在迷茫中失去了自我,开始日复一日地打游戏,因为当时上数学课觉得没有什么用,不懂为什么到了大学还是要学理论基础,看不到这些东西能在未来能给我带来什么,大二下的时候幡然醒悟,觉得自己不能再这样沉沦下去。于是重新捡起学习,一直到现在都还在还债的路上。
大二下的时候抓住一个机会,有个研究生助教找有兴趣的学生做一个项目,虽然没有帮上什么忙,但是让我接触到python了,之前学习c++并没有什么感觉,但是python的感觉不一样,学习的时候真的给我一种惊喜,之后的课设能用python写的就用python写,包括模式识别的课设(车牌识别)、中文信息处理(分词)、数据库和web技术等课设都是。现在看到当时学习的记录让我回忆起那段时光,也许就是那种喜欢才让我留下来继续学习计算机。
Python-Challenge(上)